
数组
数组可以存放多个同一类型数据,在Golang中数组是值类型。
定义方式&简单操作
// 声明一个长度为5的整型数组
var arr [5]int
// 初始化
arr = [5]int{1, 2, 3, 4, 5}
//进行数值修改
arr[1] = 100
//打印第二个元素
fmt.Println(arr[1])
//遍历打印值
for i := 0; i < len(arr); i++ {
fmt.Println(arr[i])
}注意:数组的下标是从0开始的
当然,数组定义肯定不止这一种方式,还有三种
// 方式二:直接声明并初始化,省略 var 类型(常用)
var numsArray02 = [3]int{1, 2, 3}
// 方式三:使用 ... 自动推导长度
var numsArray03 = [...]int{6, 7, 8} // 编译器自动推断长度为3
// 方式四:带索引的初始化(乱序赋值)
var names = [3]string{1: "tom", 0: "jack", 2: "marry"}数组的在内存中的分布
数组在内存中是连续存储的!所有元素按顺序一个接一个地存放,每个元素占用相同大小的空间(因为类型相同),通过首地址 + 偏移量就可以快速定位任意元素,我们可以通过直接对数组名来取地址来获得首地址。
假设我们有一个长度为 3 的整型数组:
var arr [3]int = [3]int{10, 20, 30}假设 arr 被分配在栈上,起始地址为 0x1000,每个 int 占 8 字节(64位系统),那么内存布局如下:
地址: 0x1000 0x1008 0x1010
+---------------+---------------+---------------+
| 10 | 20 | 30 |
+---------------+---------------+---------------+
arr[0] arr[1] arr[2]
指针 &arr → 0x1000当然,如果不是int类型,偏移量也会略有不同,同时因为Go的数组是值类型,所以他的内存拷贝很特别
package main
import "fmt"
func main() {
a := [3]int{1, 2, 3}
b := a // 完整拷贝!
b[0] = 999
fmt.Println("a:", a) // a: [1 2 3]
fmt.Println("b:", b) // b: [999 2 3]
}内存变化
初始:
栈帧:
+------------------+
| a: [1][2][3] |
+------------------+
b := a 后:
+------------------+
| a: [1][2][3] |
| b: [1][2][3] | ← 完全独立的副本!
+------------------+这样会导致赋值或作为参数传递时,整个数组会被拷贝一份,非常消耗性能(尤其是大数组)。
注意:这里拷贝的时候,一定是同样长度同样类型的数组,才可以互相拷贝
遍历方式
这个有什么好讲得 不就是for循环吗,看我一把梭
for i := 0; i < len(arr); i++ {
fmt.Println(arr[i])
}这里就要引用Sean得名言了,不知道Sean是谁?上链接:SeanDictionary | 折腾日记 –

Sean: 并非啊!
Golang有自己的一套独有结构,可以用来遍历访问数组的元素,没错就是窝在流程控制那一章,讲过的for-range结构
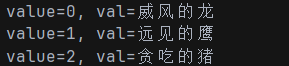
team := [...]string{"威风的龙", "远见的鹰", "贪吃的猪"}
for index, value := range team {
fmt.Printf("value=%d, val=%v\n", index, value)
}
这里补充一点,如果不需要index就用_来进行占位。
index和value的名字可以随便改,但是一般这样命名。
细节和注意事项
1.数组是多个相同类型数据的组合,一旦声明/定义了,其长度是固定的,不能动态变化。
2.var arr []int 这时 arr 就是一个 slice 切片,切片后面专门讲解,不急哈。
3.数组中的元素可以是任何数据类型,包括值类型和引用类型,但是不能混用。
4.数组的下标是从 0 开始的。
5.数组下标必须在指定范围内使用,否则报 panic:数组越界
6.Go 的数组属 值类型,在默认情况下是值传递,因此会进行值拷贝。数组间不会相互影响(上面提过的拷贝问题)
7.如想在其它函数中去修改原来的数组,可以使用引用传递(指针方式),(传址调用)
都比较好理解就不上例子了。
应用案例
1.创建一个 byte 类型的 26 个元素的数组,分别放置 'A' 到 'Z',并打印出来。
arr2 := [26]byte{}
for i := 0; i < 26; i++ {
arr2[i] = 'A' + byte(i) //这里不进行转换的话A是byte类型,i是int类型二者不能想加
}
fmt.Println("A-Z 字符数组:")
for i := 0; i < 26; i++ {
fmt.Printf("%c ", arr2[i])
}
fmt.Println()
2.求出一个数组的最大值,并得到对应的下标。
arr3 := [5]int{3, 7, 1, 9, 4}
max := arr3[0]
index := 0
for i := 1; i < len(arr3); i++ {
if arr3[i] > max {
max = arr3[i]
index = i
}
}
fmt.Printf("最大值: %d, 下标: %d\n", max, index)

3.求出一个数组的和与平均值,使用 for-range 遍历。
arr4 := [5]int{1, 2, 3, 4, 5}
sum := 0
for _, value := range arr4 {
sum += value
}
avg := float64(sum) / float64(len(arr4))
fmt.Printf("数组和: %d\n", sum)
fmt.Printf("数组平均值: %.2f\n", avg)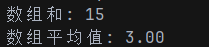
4.随机生成五个数并让其反转打印
我们这里补充一个rand函数:rand(防止看不懂英文喵改成中文文档了)
var intArr [5]int
for i := 0; i < len(intArr); i++ {
intArr[i] = rand.Intn(100)
}
fmt.Println(intArr)
我们这里确实生成个五个数,但是丝,我是不是忘了什么(好像在函数补充里面讲了随机数生成的什么东西),对的是时间戳,因为这里用的都是1.25.0的版本,从 Go 1.20 开始,Go 做了优化:如果你不手动调用 rand.Seed(),math/rand 包会自动使用一个随机种子(默认是基于时间的),所以随机数每次运行程序时是不同的,但我们这里还是加上去吧,顺便把程序完善一下。
var intArr [5]int
for i := 0; i < len(intArr); i++ {
intArr[i] = rand.Intn(100)
}
fmt.Println(intArr)
temp := 0
for i := 0; i < len(intArr)/2; i++ {
temp = intArr[len(intArr)-1-i]
intArr[len(intArr)-1-i] = intArr[i]
intArr[i] = temp
}
fmt.Println(intArr)
切片
切片在前面我们也基本的感受到了切片是个什么东西
切片是数组的一个引用,所以切片是一个引用类型,进行传递的时候,遵循引用传递机制,切片的使用和数组类似,遍历访问切片还有求切片的长度和数组都一样,但是切片的长度是可以变化的,因此切片是一个动态变化的数组。
基本语法
var a []int
//such as
var arr [5]int = [...]int{1, 22, 33, 44, 55}
slice := arr[1:3]注意这个也是包前不包后,引用的是arr数组的起始下标为1,最后的下标为3(但是不包含3)
基本使用
我们来打印一下看看。
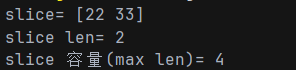
func main() {
var arr [5]int = [...]int{1, 22, 33, 44, 55}
slice := arr[1:3]
fmt.Println("slice=", slice)
fmt.Println("slice len=", len(slice))
fmt.Println("slice cap(max len)=", cap(slice))
}
这里切片的容量是可以动态变化的也就是说如果超过了容量切片就会自动增加容量(一般来说是长度的二倍也不一定)
切片在内存中的分布
在 Go 中,一个 slice 实际上是由一个 结构体(struct) 表示的,其定义如下:
type slice struct {
array unsafe.Pointer // 指向底层数组的指针
len int // 当前元素个数(长度)
cap int // 容量(最大可扩展长度)
}它本身不保存数据,只是描述一段连续内存区域的信息
假设我们有以下代码:
arr := [5]int{1, 2, 3, 4, 5}
s := arr[1:3] // 创建切片,从索引1到3(不含3),即 [2, 3] +-------------------+
| 底层数组 |
+-------------------+
| 1 | 2 | 3 | 4 | 5 |
+-------------------+
↑
|
+---------> s.array(指针)而切片 s 自身是一个结构体,在栈或堆上占据一小块空间:
+------------------+
| 切片 s |
+------------------+
| ptr → (地址) | ← 指向数组的第2个元素(值为2)
| len = 2 | ← 当前有两个元素
| cap = 4 | ← 从索引1开始,最多能用到索引5(共4个位置)当然我们可以通过一些代码来证明一下
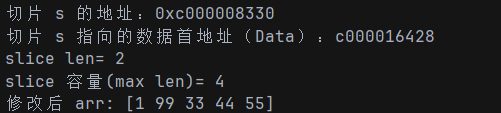
package main
import "fmt"
func main() {
arr := [5]int{1, 22, 33, 44, 55}
s := arr[1:3]
fmt.Printf("切片 s 的地址:%p\n", &s)
sh := (*reflect.SliceHeader)(unsafe.Pointer(&s))
fmt.Printf("切片 s 指向的数据首地址(Data):%x\n", sh.Data) // 这里需用 unsafe 包,简化展示
fmt.Printf("切片 s 的长度:%d\n", len(s))
fmt.Printf("切片 s 的容量:%d\n", cap(s))
s[0] = 99
fmt.Println("修改后 arr:", arr)
}Go 的设计哲学之一是 安全性和封装性,你不能直接访问 .array 或 .Data,除非使用 unsafe.Pointer 和反射(仅用于调试或底层优化)。直接打印 s.array 需要使用 unsafe 包
创建的三种方式
1.从已有的数组创建切片
通过数组的“切片操作”生成一个新的切片,新切片会共享底层数组的数据,因此它是引用类型。
slice := arr[start:end]上面演示了几遍了,不罗嗦了
2.使用 make() 函数创建切片
使用内置函数 make([]T, len, cap) 直接创建一个切片,无需依赖现有数组。
语法:
var slice []int = make([]int, len, cap)cap可以不写,但是写了就要求cap要大于等于len
make和第一种不同的点在于,这里只能通过slice去操控引用数组的内容,而不能通过数组直接进行操作,程序员是看不见的,只能通过底层来维护
3.定义切片,直接指定数组类似于make
var slice []int = []int{1,3,5}切片的遍历
1.for循环常规遍历
package main
import "fmt"
func main() {
slice := []string{"苹果", "香蕉", "橙子", "葡萄"}
fmt.Println("使用 for 循环遍历:")
for i := 0; i < len(slice); i++ {
fmt.Printf("索引 %d: %s\n", i, slice[i])
}
}2.for-range遍历
package main
import "fmt"
func main() {
slice := []string{"苹果", "香蕉", "橙子", "葡萄"}
fmt.Println("\n使用 for-range 遍历:")
fmt.Println("\n只取值:")
for _, value := range slice {
fmt.Printf("%s ", value)
}
}细节和注意事项
1.切片初始化的时候仍然不能越界,范围还是要在0~len之间但是可以动态增长
2.切片可以简写
| 完整写法 | 简写 |
|---|---|
arr[0:end] | arr[:end] |
arr[start:len(arr)] | arr[start:] |
arr[0:len(arr)] | arr[:] |
3.切片订一晚后,还不能使用因为本身是空的,一定需要让他引用到一个数组,或者make一个空间来供切片使用
4.切片可以继续切片
arr2 := [5]int{10, 20, 30, 40, 50}
slice3 := arr2[1:4]
slice4 := slice3[1:3]
fmt.Println(slice4)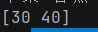
这里arr slice3和4指向的数据空间是同一个,这里对值进行改变,对三个都有影响
5.用内置函数append内置函数来对切片进行动态追加
语法:
slice = append(slice, 元素...)(1)追加单个或多个值
slice = append(slice, 10, 20, 30)将 10, 20, 30 添加到 slice 末尾。
(2)追加另一个切片(使用 ... 展开)
a := []int{100, 200}
slice = append(slice, a...) // ✅ 正确:展开为 100, 200❌ 错误写法:
slice = append(slice, a) // ❌ 类型不匹配!
...称为 展开操作符(spread operator),把切片拆成多个参数传入。
底层分析:
切片append操作的本质是对数组的扩容,检查当前切片是否有足够容量(len < cap),如果有 → 直接在底层数组末尾写入新元素。如果没有 → 触发
扩容机制:
- 创建新的更大数组(
newArr,这里是在底层维护的,程序员是不可见的) - 将原数据复制过去
- 添加新元素
- 更新切片指向新数组
返回新的切片
6.切片的复制
用copy(dst, src)函数进行复制
func main() {
var a []int = []int{1, 2, 3, 4, 5}
var slice = make([]int, 10) // 创建容量为10的空切片
fmt.Println(slice) // 输出: [0 0 0 0 0 0 0 0 0 0]
copy(slice, a)
fmt.Println(slice) // 输出: [1 2 3 4 5 0 0 0 0 0]
}| 规则 | 说明 |
|---|---|
| 只复制数据,不改变原切片 | a 仍然是 [1,2,3,4,5] |
复制数量 = min(len(dst), len(src)) | 取两个切片长度的较小值 |
| 目标切片必须有足够空间 | 否则只能复制部分数据 |
| 返回值是实际复制的元素个数 | 可用于判断是否复制成功 |
string和slice
字符串(string)在内存中:
+--------+
| a b c d |
+--------+- 存储的是字节(
byte) - 每个字符占 1 字节(ASCII 编码)
- 是不可变的,无法直接修改
切片([]byte 或 []rune)在内存中:
b := []byte("abcd")
// 内存结构:
+--------+
| a b c d |
+--------+- 可以修改元素(如
b[0] = 'z') - 是可变的动态数组
string是只读 byte 数组[]byte是可写 byte 数组
所以我们对字符串进行修改需要string转为切片修改再重写成字符串
string 与 []byte / []rune 的转换总结
| 操作 | 说明 | 示例 |
|---|---|---|
[]byte(str) | 将 string 转为 byte 切片 | []byte("abc") |
string(b) | 将 byte 切片转为 string | string([]byte{'a','b'}) |
[]rune(str) | 将 string 转为 rune 切片 | []rune("你好") |
string(r) | 将 rune 切片转为 string | string([]rune{'你','好'}) |
byte不能修改汉字,rune可以修改汉字
二维数组?切片?
多维数组这里只介绍二维数组
基本语法
二维数组:
// 声明一个 3x4 的整型二维数组
var matrix [3][4]int
// 赋值
matrix[0][0] = 1
matrix[1][2] = 5
// 遍历
for i := 0; i < len(matrix); i++ {
for j := 0; j < len(matrix[i]); j++ {
fmt.Printf("%d ", matrix[i][j])
}
fmt.Println()
}缺点:必须在编译时确定所有维度的大小,灵活性差。
二维切片:
// 创建一个动态的二维切片
var grid [][]int
// 方法1:make 初始化(指定行数)
rows, cols := 3, 4
grid = make([][]int, rows)
for i := range grid {
grid[i] = make([]int, cols)
}
// 赋值
grid[0][0] = 10
grid[1][1] = 20
// 遍历打印
for i := 0; i < len(grid); i++ {
for j := 0; j < len(grid[i]); j++ {
fmt.Printf("%d ", grid[i][j])
}
fmt.Println()
}那切片怎么添加的,和一维一样
// 每行长度可以不同(锯齿数组)
row1 := []int{1, 2}
row2 := []int{3, 4, 5, 6}
grid = append(grid, row1)
grid = append(grid, row2)
// 输出:
// [1 2]
// [3 4 5 6]内存分布
这里内存分布和C些许不同
| 特性 | C/C++ 二维数组 | Go 二维切片 |
|---|---|---|
| 存储方式 | 连续内存(按行优先) | 不一定连续,每行单独分配 |
| 灵活性 | 固定大小 | 动态可变 |
| 访问速度 | 快(缓存友好) | 稍慢(多层指针跳转) |
| 使用场景 | 高性能计算 | 一般应用开发 |










