
基本介绍
Redis (Remote Dictionary Server) 本质上是一个巨大的 Map(字典)。
- Key (键):永远是字符串(String)。
- Value (值):可以是多种数据结构(String, List, Hash, Set, ZSet)。
- 内存存储:速度极快(纳秒级),但也意味着断电会丢失(除非配置了持久化)。
- 单线程模型:Redis 的命令执行是单线程的(6.0以后网络IO有多线程,但执行命令还是单线程)。好处:不需要考虑锁的问题,它是原子性的(Atomic)。A 改数据的时候,B 绝对插不进去。
安装
我们用docker开一个容器并部署redis,端口号为6379
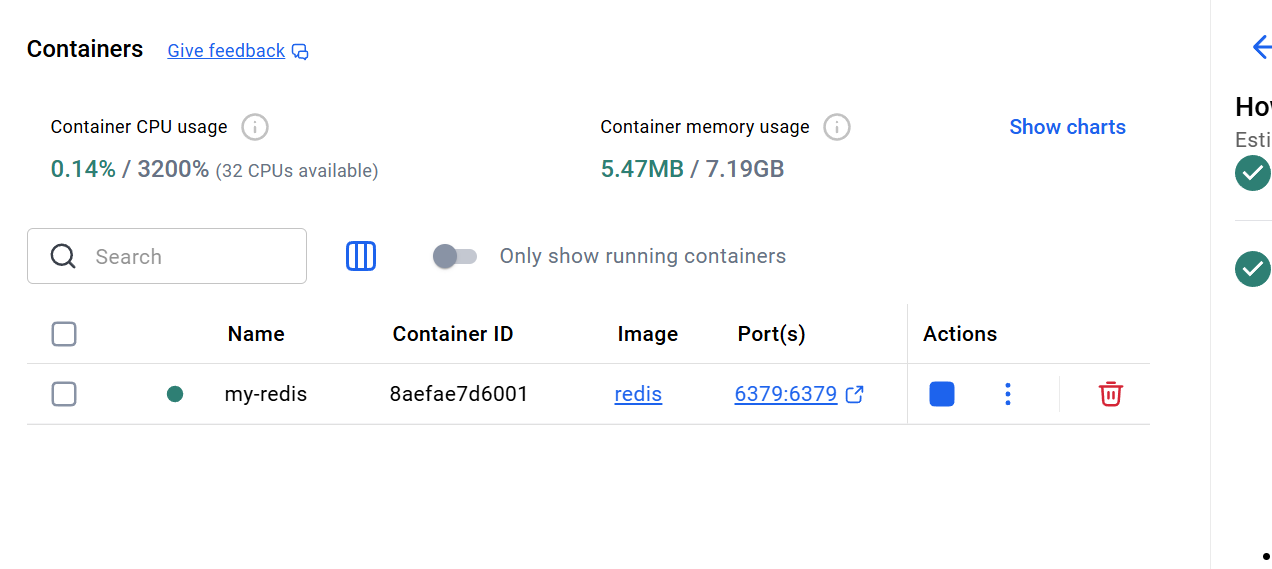
基本使用
连接及对数据库的基本操作
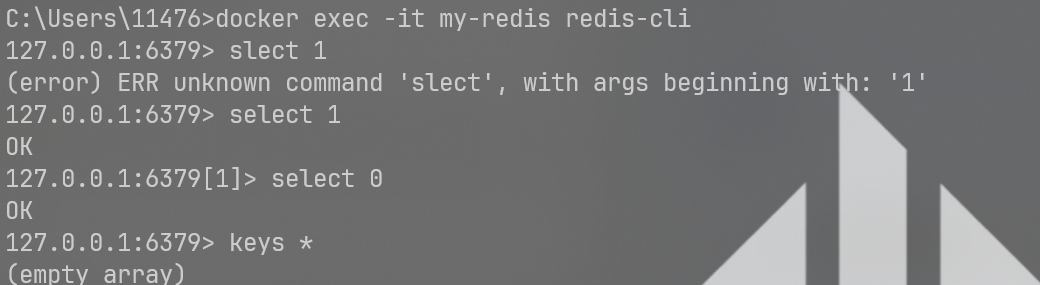
在终端连接一下
docker exec -it my-redis redis-cli- docker exec -it`: 交互式进入容器。
my-redis: 你的容器名字。redis-cli: Redis 自带的命令行客户端。
切换数据库
select 1 # 切换到 1 号库
select 0 # 切回来查看所有键
keys *注意:不要在生产环境中轻易使用
Redis是单线程,如果数据过多,会阻塞线程,导致系统卡死,线上用scan代替。
清空数据库
flushdb #清空当前库
# flushall #清空所有库删库跑路(bushi)
对string的操作
底层原理
Redis 构建了一种名为 SDS 的结构。
struct sdshdr {
int len; // 已使用的长度
int free; // 剩余的空间
char buf[];// 存数据的地方
}append 数据时,它会多分配一点空间(记录在 free 里),下次再追加就不需要重新申请内存了(高性能的关键)。
增删改查(CRUD)
1.set&get设置与获取
set k1 v1
get k1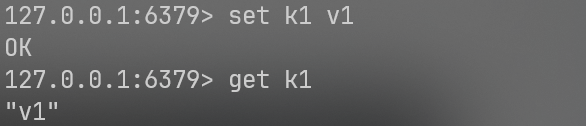
2.append追加
append k1 "play Delta Force"
get k1
返回的追加后字符串长度
3.strlen 获取长度
strlen k1
Redis 获取字符串长度是非常快的,因为底层直接存了长度。
数值操作
Redis的String存的是字节数据,但是内容看起来像是整数,Redis可以直接当作数字处理,同时因为操作时原子性的,即使有大量线程同时发请求也不对错,这就是Redis单线程模型的最大优势。
1.incr & decr (增/减 1)
set view 100
incr view
decr view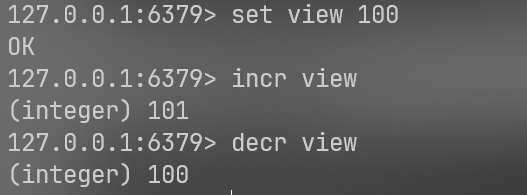
比如说用于记录访问量,点赞数等等
2.incrby & decrby (自定义增减)
incrby view 10
deceby view 10
范围操作
1.getrange (获取子串)
- 范围是 闭区间 [start, end]。
- 0 是第一个,-1 是最后一个。
set name "ttdr like to play Delta Force"
getrange name 0 -1
getrange name 0 4
2.setrange (覆盖子串)
从指定位置开始覆盖,不影响其他位置的字符。
setrange name 0 "Ttdr"
生命周期和分布式锁
重点中的重点
1.setex (Set with Expiration)
- 格式:
sex 键 秒 值
- 用于验证码的缓存数据
- 等价于
set+expire,但是setex一步到位。
setex key1 10 v1
# 查看剩余时间
ttl key1
2.setnx (Set if Not Exists)
- 格式:
setnx 键 值 - 是分布式锁的出行,如果key存在无事发生(return 0),key不存在才设置(return 1)
- 在分布式系统中,如果多个服务器同时想处理同一个订单,谁执行
setnx返回 1,谁就有资格处理。
setnx key1 "HAAVK"
del key1
setnx key1 "HAAVK"
批量操作
1.mset&mget
- 页面记载时一次性读取所有用户信息
- 可以减少网络往返时间,减少请求次数
mset k1 v1 k2 v2 k3 v3
mget k1 k2 k3
2.msetnx
要么全部成功,要么全部失败。只要有一个 key 已经存在,整个操作就全部取消。
msetnx k1 v11 k4 v4
新旧更替
1.getset
可用于重置计数,但是要知道冲之前是多少
set counter 100
getset counter 0
get counter
对Hash的操作
为什么需要哈希?
当我们存储结构体的时候,我们可以进行Json序列化一下,but我们这样要把它的年龄改成19,我就要先get,再反序列化成Json,再修改,再序列化,再set回去。好麻烦
增删改查(CRUD)
1.hset (设置字段)
格式:hset key field value
hset user:1001 name "zhangsan"
hset user:1001 age 182.hget (获取字段)
3.hmset & hmget (批量操作)
hmset 在新版 Redis 中已逐步合并入 hset,但 hmget 依然非常常用。
4.hgetall (获取所有)
- 如果 Hash 里有几万个字段,这个命令会阻塞!
- 奇数行是key,偶数行是value
hgetall user:10015.hdel (删除字段)
hdel user:1001 address
数值操作
hincrby (字段自增)
hincrby user:1001 age 1
判断和统计
1.hexists (是否存在)
hexists user:1001 address
2.hkeys & hvals (只拿键 或 只拿值)
hkeys user:1001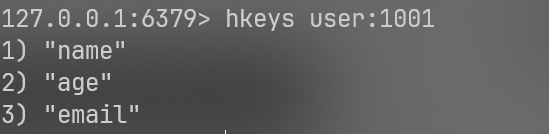
注意:Redis 的过期时间 (expire) 只能针对 Key,不能针对 Hash 里面的 Field。 如果你需要每个属性有不同的过期时间(比如验证码),就只能用 String,不能用 Hash。
对List 的操作
List是Redis实现消息队列,最新动态,排行榜的基石
底层原理:
本质上是一个双向链表,头尾插入数据会很快,但是通过下标找数据会很慢,早期的Redis使用的是标准双向链表活压缩列表,现在使用的是Quicklist的混合结构,他是用压缩列表作为节点的链表,保留了链表快速插入的特性,由避免了标注链表因为存储指针而导致的大量内存浪费。
基本操作
1.进入List
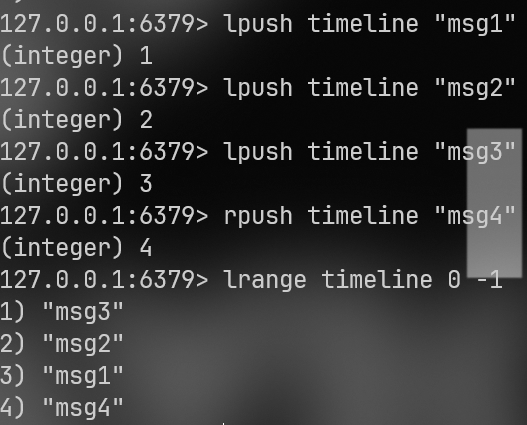
lpush头插
lpush timeline "msg1"
lpush timeline "msg2"
lpush timeline "msg3"现在的顺序是:msg3 -> msg2 -> msg1
`rpush尾插
rpush timeline "msg4"现在顺序:msg3 -> msg2 -> msg1 -> msg4
2.查看List
lrange(查看列表) ,0是第一个元素,-1是最后一个元素。
lrange timeline 0 -1只看部分(分页查询常用),lrange timeline 0 1
llen(看长度)
llen timeline
3.删除List
lpop(从头部拿走)
lpop timelinerpop(从尾部拿走)
rpop timeline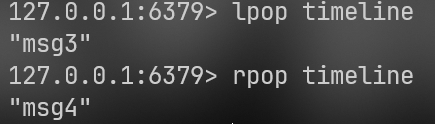
使用细节
List 强大之处在于通过组合命令,实现栈,队列,阻塞队列三种结构。
1.栈
命令:LPUSH + LPOP
特点:后进先出 (LIFO)。
场景:浏览器的“后退”按钮,刚才看的页面在最上面。
2.队列
命令:LPUSH + RPOP
特点:先进先出 (FIFO)。
场景:消息队列。生产者在左边拼命塞任务,消费者在右边排队拿任务处理。
3.阻塞队列 (Blocking Queue)
blpop / brpop 如果你用普通的 lpop,如果列表是空的,它返回 nil,你还得写个 for 循环不停地轮询(空转),浪费 CPU。 blpop 会阻塞住连接,直到列表里有数据,或者超时。
对Set(集合)的操作
核心特性
继承了高中数学优秀的集合性质,有去重和无序的特性,多次输入重复数据只记录一个值,录入的数据不存在任何逻辑顺序。
基本使用
我们用一个文章标签来做个例子
1.sadd :添加
sadd tags:1001 "Tech" "Coding" "Docker"
sadd tags:1001 "Tech"
2.smembers :查看所有
smembers tags:1001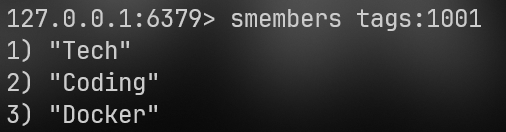
3.sismember :判断是否存在:
sismember tags:1001 "Java"
sismember tags:1001 "Docker"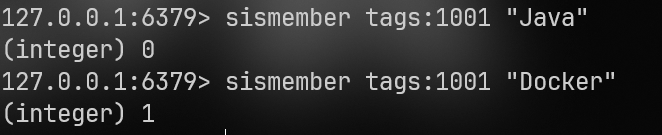
4.scard :获取个数
scard tags:1001
5.`srem :删除元素
srem tags:1001 "Tech"
集合运算(没错就是那个集合运算)
交集:sinter
sinter me you并集:sunion
sunion me you差集:sdiff
sdiff me you
sdiff you me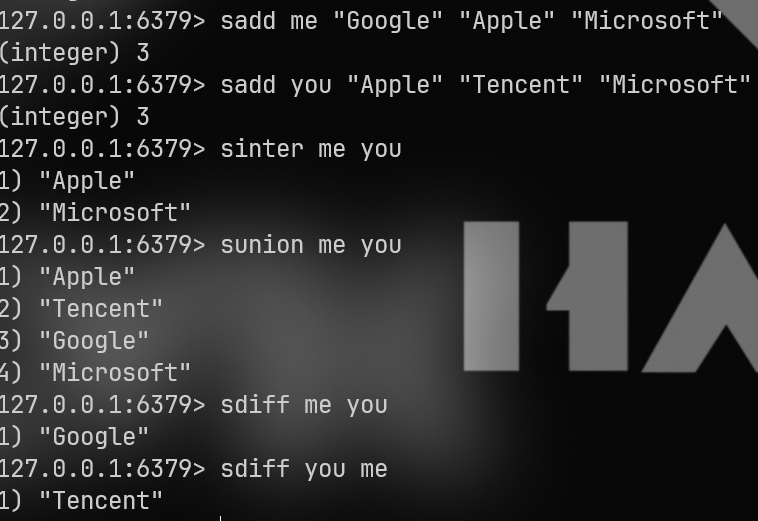
随机抽取
有放回抽取:srandmember
srandmember users 2无放回抽取:spop
spop users 1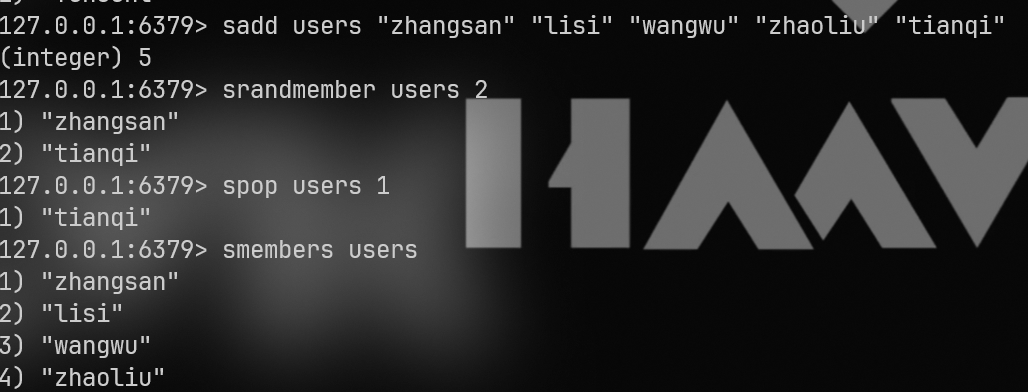
底层分析
当我们存储一个数量比较少的时候,我们取出来的时候,他可能去取出的是有序的?这是为什么
Set 的两种编码:
1.Intset (整数集合):
当集合里全是整数,且数量较少(默认 < 512)时,Redis 为了省内存,会用一个有序的数组来存,所以这时候它其实是有序的!*
2.Hashtable (哈希表):
一旦你存了一个非数字(比如 “a”),或者数字太多,编码立刻变成 hashtable,这时候就是真正的无序了。
对Zset 的基本操作
核心特性
1.自带“权重”:在 Set 的基础上,给每个元素加了一个 Score(分数/权重)。
2.自动排序:数据存进去,自动按 Score 从小到大排好队。
基本使用
以“编程语言热度榜”为例:
1.zadd (添加/更新):
格式:zadd key score member
zadd rank 100 "Java" 90 "Go" 80 "Python"2.zrange / zrevrange (查看排名):
zrange:从小到大(倒数排名)。zrevrange:从大到小(正数排名)。
zrevrange rank 0 -1 withscores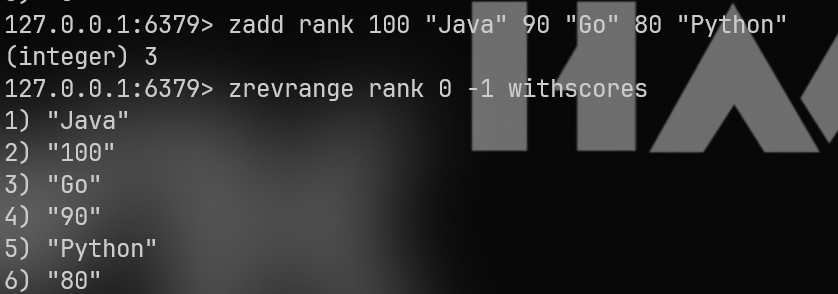
3.zincrby (动态加分):
直接改分数,排名自动变,不需要重新排序。
zincrby rank 50 "Go"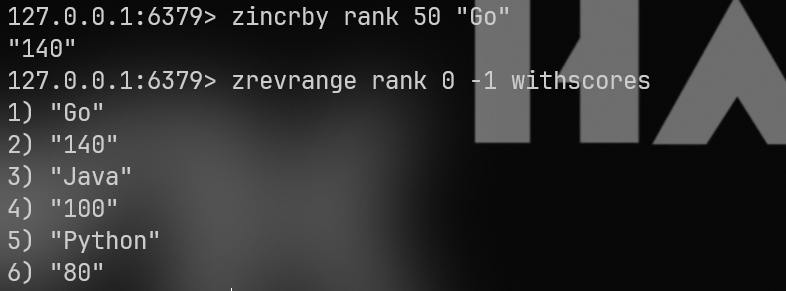
4.zrem (删除):
zrem rank "Python"
范围与定位
1.zrangebyscore (按分数查):
zrangebyscore rank 80 100
2.zrank / zrevrank (查具体第几名):
- 返回 0(代表第1名,因为索引从0开始)
zrevrank rank "Go"
底层分析
edis 怎么做到插入一个新分数,瞬间就能排好序?
Redis 这里使用了一种极其精妙的数据结构:SkipList (跳表,跳表就是给链表加了“多级索引”)。
当然,如果元素很少(默认 < 128 个)且很短,Redis 依然会使用 Ziplist (为什么又是他) 来省内存。只有数据多了,才会升级为 SkipList。
为啥不用红黑树?
Java 的 TreeMap用红黑树。Redis 作者认为红黑树代码太复杂,且在范围查找(Range)时效率不如跳表。




